 全渠道智能客服
全渠道智能客服

 AI客服机器人
AI客服机器人
 客服电话呼叫中心
客服电话呼叫中心
 微工单系统
微工单系统
 网站客服
网站客服
 微信客服
微信客服
 视频客服
视频客服
 APP客服
APP客服
 小程序客服
小程序客服
 微客服
微客服
 微营销
微营销
 智能语音机器人
智能语音机器人
 客服外呼系统
客服外呼系统
 智能质检
智能质检
 数据大屏
数据大屏
 新零售&电商
新零售&电商
 金融保险
金融保险
 教育培训
教育培训
 生活服务
生活服务
 汽车出行
汽车出行
 企业服务
企业服务
 大型国企
大型国企
 新闻动态
新闻动态
 行业聚焦
行业聚焦
 产品速递
产品速递
 帮助中心
帮助中心

随着人工智能技术的快速发展,LLM(大语言模型)驱动的智能客服系统正逐步成为企业数字化转型的核心工具。这类系统凭借其强大的自然语言处理能力、高效的交互效率以及持续优化的学习机制,正在重塑企业与客户之间的沟通模式。
然而,面对市场上种类繁多的解决方案,如何筛选出符合企业实际需求且具备长期应用潜力的大语言模型客服系统,成为决策者需要深入思考的问题。本文将从技术能力、智能化水平、安全合规性及服务支持四大维度,解析企业在选型过程中应关注的核心要素。

一、LLM大语言模型驱动的智能客服系统
大语言模型客服系统的核心在于其底层的人工智能架构。这类系统基于大规模预训练语言模型,能够通过海量数据学习人类语言的语法、语义及上下文逻辑,从而实现拟人化的对话交互。与传统规则型客服系统不同,大语言模型客服无需依赖预设的固定问答库,而是通过实时解析用户意图生成动态回应,显著提升了服务灵活性和覆盖场景的广度。
此外,大语言模型客服的自我迭代能力使其能够随着业务场景的变化持续优化。例如,系统可通过分析历史对话数据,主动识别高频问题并调整应答策略,或根据用户反馈修正对话中的潜在偏差。这种动态适应能力为企业提供了长期的技术红利,尤其适合需求快速变化的行业。
二、关键评估维度一:系统性能与功能
在评估大语言模型客服系统时,性能表现是决定用户体验的核心指标。首先需关注模型的响应速度与稳定性。理想的系统应在毫秒级内生成连贯、准确的回复,并能在高并发场景下保持服务可用性。对于存在海外业务的企业,还需验证系统对多语言的支持能力,包括方言识别和专业术语的理解深度。
功能层面,需重点考察系统的场景适配性。优秀的大语言模型客服应具备多模态交互能力,例如整合文本、语音、图像等多种输入方式,并能根据不同业务场景切换服务模式。此外,是否支持知识库的动态更新、意图识别的颗粒度、以及复杂问题的拆解能力,都是衡量系统功能完整性的关键要素。
三、关键评估维度二:智能程度与学习能力
大语言模型客服的差异化竞争力在于其智能化水平。企业需评估系统的语义理解精度,包括对模糊表述的解析能力、上下文关联性的捕捉能力,以及多轮对话中的逻辑一致性。例如,系统是否能区分用户提问中的隐含需求,或在对话中途主动澄清歧义信息。
学习能力的评估则需关注模型的持续优化机制。一方面,系统应支持增量训练,能够通过新数据快速更新知识储备;另一方面,需具备主动学习能力,例如自动识别知识盲区并触发人工标注流程。同时,企业应考察系统的个性化适配能力,例如能否根据客户画像调整应答风格,或在垂直领域形成专业化知识体系。
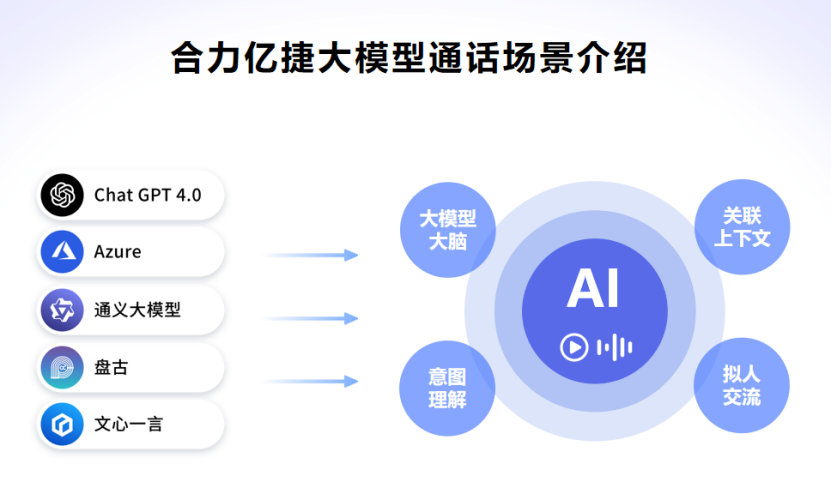
四、关键评估维度三:数据安全与隐私保护
部署大语言模型客服系统时,数据安全是企业不可忽视的底线要求。首先需确保系统满足国内外数据合规标准,例如GDPR、网络安全法等法规对数据存储、传输及处理的强制性规定。技术层面,需验证系统是否采用端到端加密、权限分级管控、审计日志追踪等防护机制。
在隐私保护方面,需重点关注用户数据的匿名化处理能力。大语言模型客服应具备敏感信息过滤功能,例如自动遮蔽身份证号、银行卡号等隐私字段,并在模型训练中彻底脱敏原始数据。此外,企业需明确供应商的数据使用边界,避免因第三方留存对话记录导致合规风险。
五、关键评估维度四:服务与售后支持
大语言模型客服系统的落地效果不仅取决于技术能力,更与供应商的服务水平密切相关。在售前阶段,供应商需提供精准的需求诊断能力,协助企业梳理业务场景与技术目标的匹配路径。部署阶段,则需考察其系统集成效率,例如是否支持与企业现有CRM、ERP等系统的无缝对接。
售后支持体系需覆盖系统的全生命周期管理。包括定期算法迭代、故障应急响应机制、以及定制化功能开发支持。此外,供应商应提供完善的培训资源,例如操作手册、技术白皮书、在线课程等,帮助企业快速培养内部运维团队。对于复杂业务场景,是否配备专属技术顾问进行持续优化,也是衡量服务能力的重要指标。
总结:
选择适配的大语言模型客服系统是一项需要兼顾技术前瞻性与业务实用性的战略决策。企业需从性能、智能、安全、服务四大维度建立系统化的评估框架,既要关注当下需求,也要预判未来三年的技术演进方向。
亿捷云客服基于AI大模型驱动智能客服机器人,集成了自然语言处理、语义理解、知识图谱、深度学习等多项智能交互技术,解决复杂场景任务处理,智能客服ai,精准语义理解,意图识别准确率高达90%。
如需智能客服、AI客服机器人产品,请联系【亿捷云智能客服】,联系电话: 4006-345-690















