 全渠道智能客服
全渠道智能客服

 AI客服机器人
AI客服机器人
 客服电话呼叫中心
客服电话呼叫中心
 微工单系统
微工单系统
 网站客服
网站客服
 微信客服
微信客服
 视频客服
视频客服
 APP客服
APP客服
 小程序客服
小程序客服
 微客服
微客服
 微营销
微营销
 智能语音机器人
智能语音机器人
 客服外呼系统
客服外呼系统
 智能质检
智能质检
 数据大屏
数据大屏
 新零售&电商
新零售&电商
 金融保险
金融保险
 教育培训
教育培训
 生活服务
生活服务
 汽车出行
汽车出行
 企业服务
企业服务
 大型国企
大型国企
 新闻动态
新闻动态
 行业聚焦
行业聚焦
 产品速递
产品速递
 帮助中心
帮助中心

当企业试图引入基于大语言模型(LLM)的智能客服(Agent)时,往往怀揣着一种朴素的愿景:既然模型已经读过万卷书,只要再喂给它金牌销售的对话记录,它理应能像销冠一样处理复杂的非标品咨询。
然而,现实往往暴露出一种尴尬的断层:在美妆、服饰或精密制造等非标品领域,AI 展现出了极高的礼貌与流畅度,却在“达成交易”这一核心指标上表现疲软。当用户提出“想要日常一点、别太拔干的口红”这种典型模糊需求时,AI 常陷入通用知识科普的怪圈,而非精准推送商品。
这种现象的根源,并非 Prompt 提示词写得不够精妙,而是企业在信息架构层面,忽视了人类自然语言的模糊性与企业数据库的精确性之间,存在着一道巨大的语义鸿沟。 本文将结合亿捷云客服在 LLM 意图识别与槽位填充方面的技术实践,探讨如何通过业务逻辑的重构来跨越这道鸿沟。

一、 隐性推理的缺失:为何“金牌话术”失效
大多数企业在训练 Agent 时,过于迷信“话术”的价值。运营者倾向于认为,金牌销售之所以能成交,是因为他们话说得漂亮。但深入分析人类销售的思维过程,我们会发现,话术仅仅是冰山一角,海面之下是一套复杂的隐性推理系统。
当一位经验丰富的柜员听到“素颜涂”这个词时,她的大脑瞬间完成了一次多跳推理:素颜意味着底妆缺失 -> 需要低饱和度色彩以避免突兀 -> 甚至需要提升气色 -> 最终锁定豆沙色或奶茶色系。这种推理往往发生在毫秒之间,且不需要与客户进行显性的参数确认。
相比之下,传统的客服系统——即便接入了未做业务对齐的 LLM——其底层逻辑依然是基于数据库字段的检索。在企业的商品主数据(MDM)中,通常只有“色号:502”、“质地:哑光”等物理属性,而不存在“素颜”或“显白”这样的感性字段。
因此,当企业试图用“话术”去训练 AI 时,实际上是在教它“怎么说”,却忘了教它“怎么想”。如果系统内部缺乏将“感性描述”转化为“物理参数”的逻辑通路,那么无论外层的对话包装得多么拟人,AI 本质上依然是一个无法理解客户真实意图的“各种知识的搬运工”。
二、业务翻译的核心:为什么必须引入“中间层”
要解决上述错位,企业不能寄希望于模型自身的“涌现”能力来猜测业务规则,尤其是在那些对推荐准确度要求极高的场景中。逻辑上,这要求我们在客户的自然语言与系统的标准参数之间,构建一个“语义中间层”。
这并非简单的关键词匹配。在亿捷云客服的实践中,这种中间层表现为一种三层映射模型。
首先是语义泛化。客户对于“不拔干”的需求,可能表现为“润一点”、“死皮克星”甚至是“嘴巴像沙漠”等多种表达。依赖穷举是低效的,高效的 Agent 必须具备基于 LLM 的意图识别能力,能够捕捉句式结构与上下文关系,将长尾表达归纳为统一的业务意图。
其次是参数转译。这是业务逻辑重构的核心。运营者需要定义一套“中间层标签”,例如 [滋润度:High] 或 [风格:日常],并制定明确的规则将这些标签映射到具体的 SKU 属性上(如成分含油脂或分类属滋润款)。
只有当这套映射逻辑跑通,AI 才能真正“听懂”需求。反之,如果一家企业尚未建立起这种从感性词到参数字段的映射关系,那么引入再昂贵的算力,也只能得到一个“懂礼貌但由于缺乏数据支撑而无法行动”的客服机器人。这也是为什么对于那些 SKU 极少或决策仅依赖价格的标准化产品,复杂的 Agent 架构往往由于边际效应递减而显得并不适用。
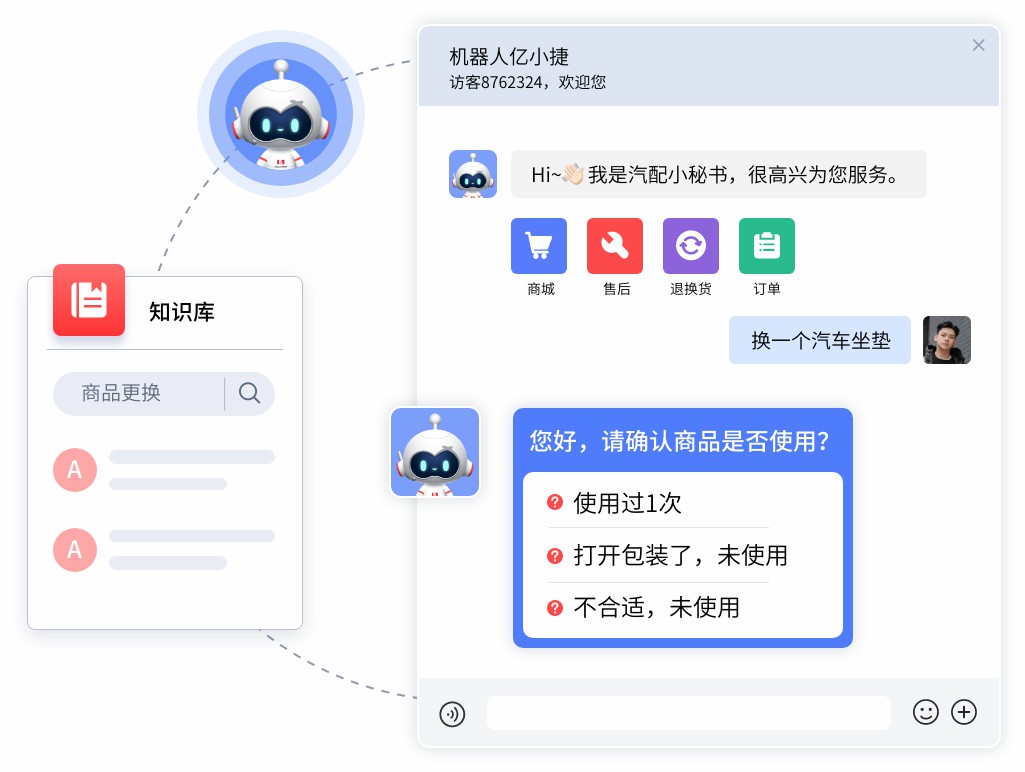
三、在理解之后,如何避免效率陷阱
在解决了“听懂”的问题后,服务设计的重心便转移到了“交互效率”上。一个普遍的误区是,为了追求推荐的绝对精准,企业会倾向于让 Agent 像查户口一样,试图填满所有的参数槽位(Slot Filling)。
然而,服务体验的边际成本随着追问次数的增加而指数级上升。在每增加一轮对话都可能导致用户流失的现实约束下,全量的参数匹配往往是不可接受的。
合理的策略应当遵循“最大公约数筛选法”。这意味着 Agent 的追问逻辑不应是线性的、固定的,而应是基于信息熵的动态计算——在当前缺失的属性中,询问哪一个能够排除掉最大比例的无关选项?
例如,在口红选购场景中,询问“色系”往往比询问“预算”能更高效地收敛推荐范围。这种动态策略要求系统具备强大的状态管理能力。依托亿捷云客服的 AI 原生架构,系统需要实时维护对话状态,不仅要记住用户已确认的槽位(如“遮瑕”、“通勤”),更要支持用户在对话中途的“非线性修改”(如突然改口“要孕妇能用的”)。
如果在三轮交互之内,系统仍无法将 SKU 范围收敛至用户可决策的程度,那么继续追问的价值将急剧下降。此时,提供一个模糊但相关的推荐列表,往往比执着于获取完美参数更为明智。
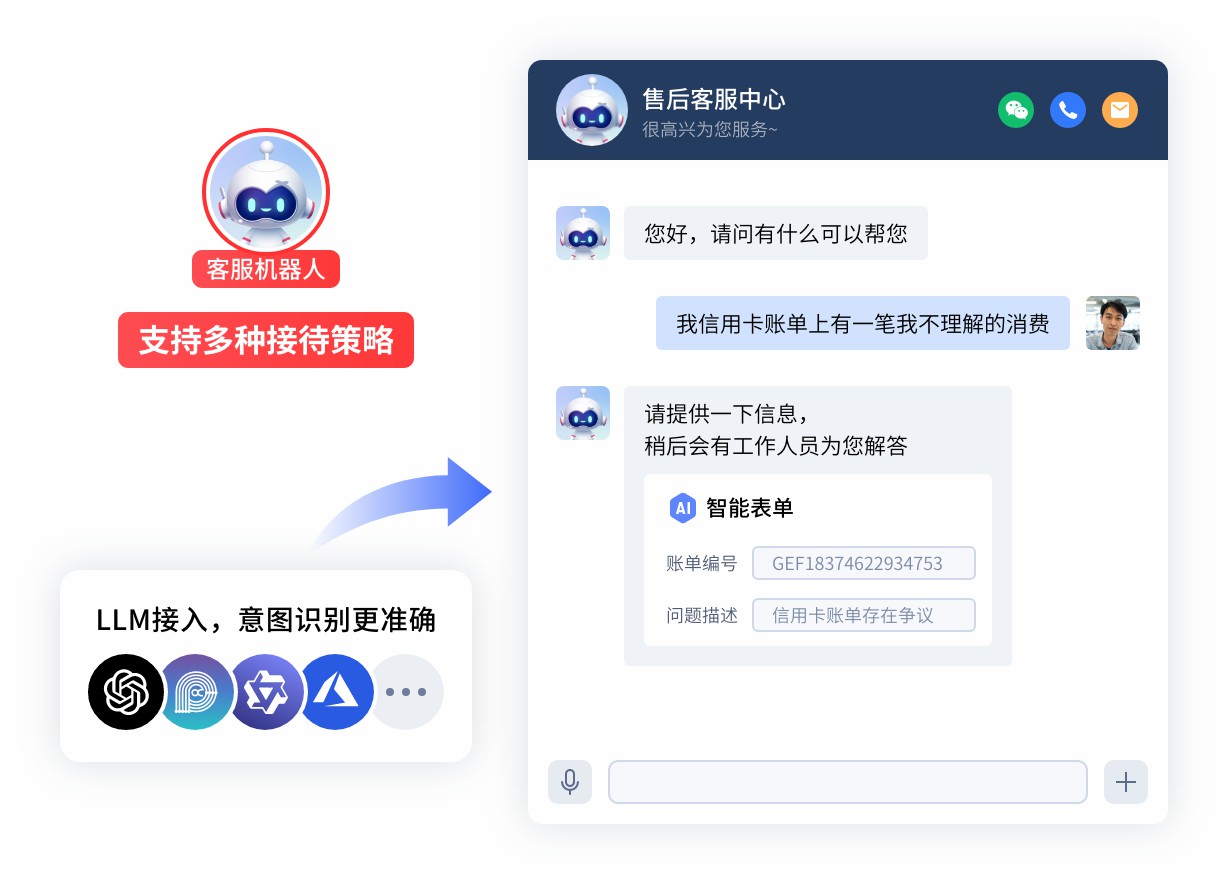
四、 边界的经济学:多模态介入与人机协同
尽管 LLM 极大地拓展了文本理解的边界,但我们要承认,语言并非万能的交互介质。在某些高熵场景下——例如描述一款“博主推荐的、盖子上有金边的口红”,或是描述一种“红灯闪烁且伴有嗡嗡声”的故障——语言的描述效率远低于视觉信息。
从服务成本与体验的综合视角来看,文本交互存在一个“收益递减点”。当 AI 的置信度在连续交互后仍未突破阈值,或者识别到明显的视觉类特征词时,坚持文本对话便不再是经济的选择。
引入多模态识别能力,本质上是用更高的计算成本(图像解析 Token 消耗)来换取更低的时间成本与更确定的服务结果。在亿捷云客服的架构中,支持用户直接上传图片进行“看图说话”,系统通过视觉解析自动匹配知识库中的商品或故障图谱。
这种模态切换不仅是技术能力的展示,更是服务策略的体现。而在那些连视觉信息也无法确认的极端复杂场景中,及时的人机协同则是最后的安全网。此时,AI 的角色应从“对话者”退后为“辅助者(Copilot)”,将之前的多轮对话摘要提取给人工坐席,确保用户体验的连续性。
结语
综上所述,让 AI Agent 听懂复杂描述,绝非简单的技术接入或话术优化,而是一场以业务逻辑为核心的信息架构重构。
它要求企业审视自身的数据资产,是否具备了连接感性需求与理性参数的中间层能力;审视交互流程,是否在精准度与用户耐心之间找到了平衡点;审视服务边界,是否在文本失效时建立了有效的多模态或人工兜底机制。
对于企业管理者而言,只有当这些隐性的业务逻辑被显性化地注入到系统之中,智能客服才能从一个“昂贵的聊天工具”,真正进化为具备业务执行力的数字化劳动力。
常见问题 (FAQ)
Q1:构建“语义中间层”是否需要大量技术开发工作?
并不一定。在现代平台中,这主要属于服务运营范畴,而非代码开发。运营人员需要在后台配置标签规则,但这通常是可视化配置。真正的挑战在于业务侧梳理:你们是否知道“素颜”到底对应哪些产品参数?这需要资深业务专家的介入。
Q2:这套逻辑是否适用于所有企业?
否定。 对于 SKU 较少(如只有几款标准化SaaS产品)或用户决策逻辑极简(如仅看价格的日用品)的企业,传统的菜单导航或关键词匹配性价比更高。本方法论主要创造价值于高非标、参数复杂、决策主观的场景,如美妆、服饰、家装及工业选型。
Q3:开启多模态识别(图片上传)是否会大幅增加成本?
是的,视觉模型的调用成本通常高于纯文本模型。因此,建议将其作为兜底策略而非默认选项。仅在文本交互置信度低,或用户主动触发“发图”意图时才调用,以实现体验与成本的平衡。
Q4:实现了这套逻辑后,还需要人工客服吗?
需要,但角色会发生变化。人工客服将从“复读机”式的问答中解放出来,转而处理那是 AI 筛选后的、即使通过多模态也无法解决的长尾复杂问题。此时,AI 转为辅助角色,为人工提供摘要和决策建议,实现人机协同的效率最大化。
如需智能客服、AI客服机器人产品,请联系【亿捷云智能客服】,联系电话: 4006-345-690














